Abstract
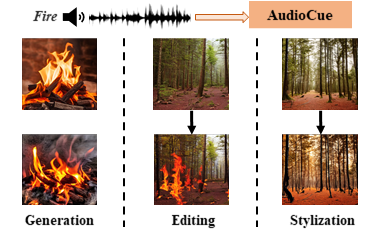
Diffusion models have significantly advanced various image generative tasks, including image generation, editing, and stylization. While text prompts are commonly used as guidance in most generative models, audio presents a valuable alternative, as it inherently accompanies corresponding scenes and provides abundant information for guiding image generative tasks. In this paper, we propose a novel and unified framework named Align, Adapt, and Inject (AAI) to explore the cue role of audio, which effectively realizes audio-guided image generation, editing, and stylization simultaneously. Specifically,AAI first aligns the audio embedding with visual features, and then adapts the aligned audio embedding to an AudioCue enriched with visual semantics, finally injects the AudioCue into existing Text-to-Image diffusion model in a plug-and-play manner. The experiment results demonstrate that AAI successfully extracts rich information from audio, and outperforms previous work in multiple image generative tasks.
Method
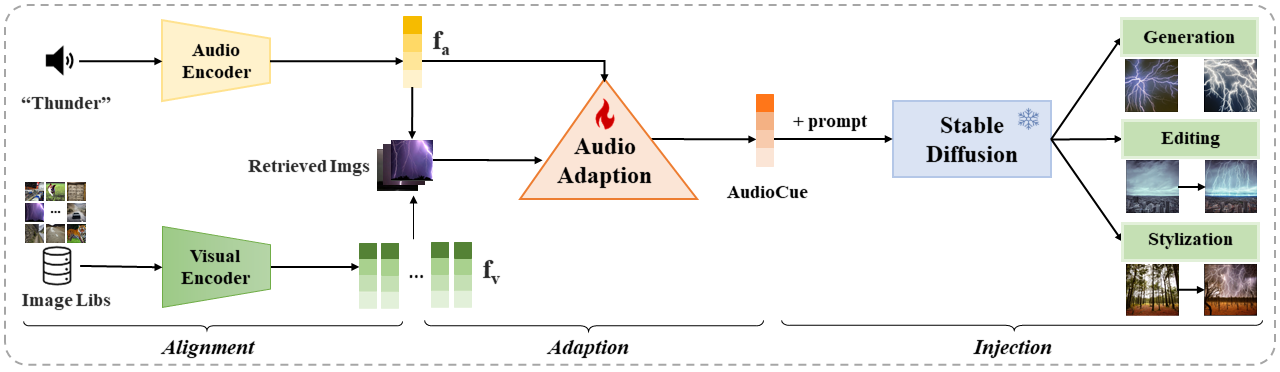
we propose a unified framework named AAI extracting AudioCue and leveraging the cue role of audio for existing T2I diffusion models to accomplish image generation, image editing, and image stylization, as illustrated in the above framework. Specifically, AAI first generates the audio embedding which aligns well with the visual branch through contrastive training. Then, we introduce an adapter for each audio embedding to quickly adapt it to an AudioCue under the supervision of a few retrieved images. The adaption process can enrich specific semantics in images into the AudioCue. The obtained AudioCue can be injected into T2I models plug and play to achieve various image manipulation tasks effectively and efficiently. Experimental results show that AAI outperforms other audio-guided methods in CLIPScore and ImageReward Score.
We aim to implement an audio-guided generative framework by injecting an AudioCue as nouns, verbs, and adjectives into existing T2I models, to achieve image generation, editing, and stylization simultaneously. To this end, we introduce AAI, which aligns and adapts the input audio to produce AudioCue, and then injects the AudioCue into the T2I diffusion model. As shown in the figure above, AAI mainly consists of three stages: (i) Audio Alignment (ii) Audio Adaption, and (iii) Audio Injection.
Generation Results
As demonstrated in these generated images, when adopted for image generation, the AudioCue can effectively capture the semantics of corresponding nouns in the audio, such as scenery (seawave) and objects (fireworks). The generated images are diverse in shapes and colors, providing sufficient details






As figure below shows, AAI can successfully and vividly extract visual information in audio, outperforming other audio-guided image manipulation methods (recent AT [ 6]), and sometimes behave better than SDM. The right part of figure below verifies that the image generated by AAI is more preferred by users and succeed in image naturalness.

Editing Results
In terms of image editing, we inject the AudioCue into source prompts, they turn into “A ∗ city”, and “A ∗ tiger”. It is obvious that the thunder is added above the city and the tiger opening its mouse, embodying the AudioCues can act as verbs. It’s worth noting that our model can preserve the other pixels completely, which is valuable for image editing.



Stylization Results
As for image stylization, typical scenes are that different weathers usually accompany specific audios. Here, we show that our AudioCue can hint an abstract style, like an adjective to render a whole image. Below the stylied images shows the car is turned driving in the misty rain and the forest is tinged with fiery red by adding “in the style of ∗” after the original prompts.



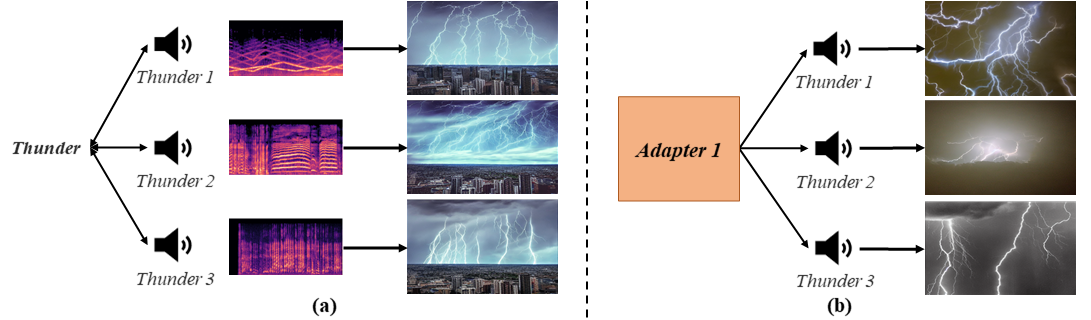
Different Sound in Same Label
As depicted in figure below, the fourth line represents images generated by our model, which are tailored to each distinct audio input. In contrast, the third line corresponds to the relative version, where we eliminate the audio adapter while keep all other settings unchanged, so it only uses reference images to invert the vision-based representation. It is evident that our model adeptly captures the dynamic semantic information conveyed by the audio input, resulting in more extreme outcomes, such as a more fiercely growling tiger. Without the audio adapter, despite maintaining all other settings, the generated images still struggle to capture more than the most salient features, lacking the detail necessary for generating finer attributes. This limitation arises primarily because each audio sample possesses its unique context, thus offering guidance that is richer than a vision-based representation alone.